인코딩 관련 이슈 발생
진행하고 있는 프로젝트에서 댓글 관련 테스트를 진행하는 도중 댓글을 입력하는 시점에는 문제없다가 댓글을 저장 후 서버로 부터 응답 받은 댓글이 깨지는 이슈가 발생했다. 서버팀에 문의하니 로깅 시스템을 추가하는 과정에서 모든 요청 데이터의 인코딩/디코딩 방식이 잘못되어 발생한 이슈라고 답변받았다. 음… 이 기회에 인코딩/디코딩 개념을 잡고가자!
텍스트 인코딩/디코딩
먼저 이슈가 발생한 텍스트 인코딩/디코딩에 대해서 알아보자! 컴공 수업 때부터 무수히 많이 들었던 말이 있다. 컴퓨터는 1과 0밖에 모른다는 그 말… 그렇다고 사람이 0과 1로 텍스트를 작성한다면 너무 끔찍하지 않은가? 따라서 사람이 편하게 텍스트를 입력할 수 있게하기 위해 텍스트 인코딩/디코딩이 등장하게 되었다.
ASCII의 등장
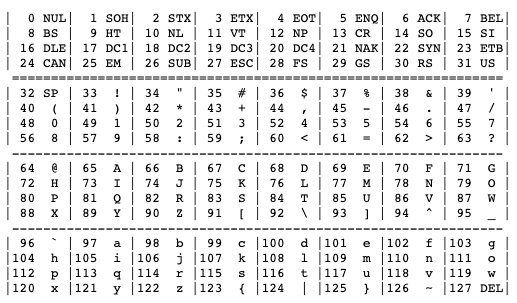
이진 데이터와 문자를 매핑한 표(Character Set)가 1963년 미국 ANSI에서 등장했다. 각 문자는 7bit(0~127)로 표현할 수 있는 숫자와 매핑된다. 해당 표에 약속한 규칙에 따라 텍스트를 이진 데이터로 변환하는 과정이 인코딩, 반대로 이진 데이터를 텍스트로 변환하는 과정이 디코딩이라고 한다.
위에서 언급한 이슈는 인코딩에 사용한 캐릭터 셋과 디코딩에 사용한 캐릭터 셋이 달라서 문자가 깨지는 현상이 발생한 것으로 추측된다.
Unicode의 등장
초기에는 알파벳과 숫자, 일부 특수문자만 정의한 ASCII 캐릭터 셋으로 충분했지만, 컴퓨터 보급이 활발해지고 나라마다 컴퓨터를 이용하게 되면서 알파벳 외 다른 나라의 문자도 컴퓨터에 표현해야 했다. 따라서 국제적으로 전 세계 언어를 모두 포괄하는 캐릭터 셋인 Unicode가 등장하게 되었다. Unicode는 기존 ASCII와도 호환되었다.

개발하면서 자주 보았던 UTF-8은 Unicode 캐릭터 셋을 기반으로 한 인코딩 방식이다. UTF-8은 가변 인코딩 방식을 사용한다. 가변 인코딩 방식은 메모리 낭비를 줄이기 위해 고안되었다. Unicode는 총 4byte로 문자를 표현하는데 기존 ASCII에 포함된 알파벳은 1byte로 충분히 표현할 수 있다. 그런데 4byte를 모두 사용하게 되면 메모리가 낭비되므로 알파벳은 1byte로 표현한다. 각각 문자마다 사용하는 byte가 달라지므로 구분하기 위한 규칙이 필요한데 그 규칙은 위 표와 같다.
파일(미디어) 인코딩/디코딩
Base64
MIME Type
본래 이메일과 함께 동봉할 파일을 텍스트 문자로 전환해서 이메일 시스템을 통해 전달하기 위해 개발되었다. 현재는 웹을 통해서 여러 형태의 파일을 전달하는 데 쓰이고 있다. ‘어떤 마임 타입(MIME type)은 웹브라우저에서 지원된다, 안된다.’ 이 말은 ‘특정 콘텐츠 타입의 파일을 웹 서버로부터 전달받아서 웹 브라우저가 열 수 있다, 없다’라는 의미와 동일하다. MIME으로 인코딩한 파일은 Content-type 정보를 앞부분에 담게 되며 Content-type은 여러 가지 타입이 있다. 즉, Content-Type은 MIME 타입으로 변환된 문서의 종류를 의미한다.
Base64 인코딩은 MIME 타입에서 사용하는 인코딩 방식으로 바이너리 데이터(원본)을 ASCII 문자로 변환한다. MIME Type의 자세한 설명은 여기를 확인하자!
Base64는 바이너리 데이터를 6bit씩 끊어서 몽땅 영문자(8bit)로 만드는데 아래 예시를 보자!
예) 텍스트 파일에 CHS 문자열이 있다고 가정
→ C(67): 01000011, H(72): 01001000, S(83): 01010011
→ 바이너리 데이터 : 01000011 01001000 01010011
→ 6bit로 쪼개기 : 010000 110100 100001 010011
→ ASCII 문자로 변환 : Q0hT
위의 예시는 마지막이 6bit로 딱 떨어지지만 그렇지 않은 경우 padding(=) 값을 붙힌다.
왜 Base64를 사용할까?
6bit를 ASCII(8bit)로 표현하기 때문에 용량 오버헤드가 발생한다. 그런데도 왜 사용할까?
ASCII는 패리티 비트를 제외하면 7bit 인코딩이다. 나머지 1비트를 시스템별로 상이하게 처리하지만, Base64는 6bit(64)로 안전한 출력 문자만 사용할 수 있다. 따라서 정보를 주고받을 때 신뢰성 있는 데이터 통신을 할 수 있다.
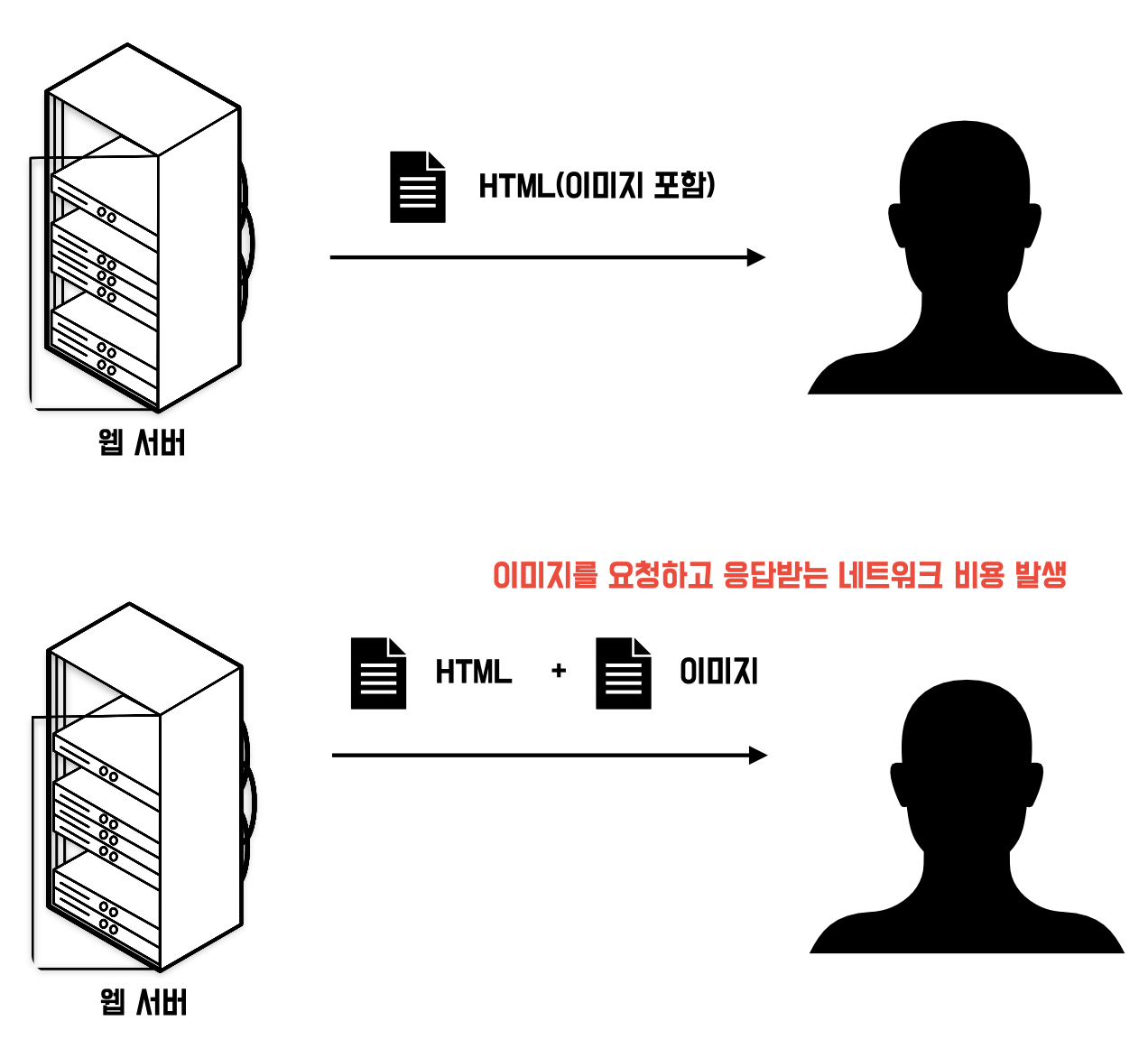
HTML 문서에 바이너리 데이터(작은 이미지와 같은)를 포함하기 위해 사용한다. 아래 이미지를 보면 HTML에 이미지를 포함한 경우 네트워크 비용을 절약할 수 있다. 내 생각에 바이너리 데이터를 HTML 문서에 포함하지 못하는 이유는 바이너리 데이터를 문자열로 변환하는 과정이 필요하고 그렇게 되면 압축하지 않은 엄청나게 긴 바이너리 데이터가 HTML 문서에 포함되어 전송 효율을 떨어트릴 것 같다고 생각한다.
![]()